As I usually do around this time of year, I took a much-needed one-week vacation from work at the beginning of May. With my recent scaling-back of the rosco_m68k project that’s been getting all my free time for the past couple of years, I needed a fun project to do during my time off, and I ideally wanted to take a break from Motorola 68k assembly and electronics and do something different.
Note: This is a pretty long post - if you don't feel like reading this wall of text and instead just want to see the code and some examples, check the project out on Github.
With that in mind, I decided I wanted to write a modern assembler for the JVM! I’ve been quietly maintaining this version of Jasmin for the past couple of years (though I’ve not really done much other than respond to an issue) via my involvement in the Code Shelter project, and while Jasmin is a venerable project with good usage, it’s getting quite long in the tooth now, and adding support for modern JVM features is tricky at best.
With that in mind, and week of free time stretching out in front of me, I decided I was going to see how far I could get with a brand-new assembler. My initial goals were:
- Use ANTLR4 for lexing and parsing
- User ASM 9.x for class generation
- Support all JVM instructions (including
INVOKEDYNAMIC) and modern features (such as dynamic constant pool entries) - Have a nice syntax (Jasmin’s
.classsyntax for example always bugged me slightly)
I specifically wanted to use ANTLR4 as I haven’t had chance to really play with it, but I had a lot of fun with v3 a while ago and felt like updating my skills. I also wanted to refresh my skills with ASM, which I’ve used for quite a bit of code generation in the past but seldom get to use in the current day job.
In case I got the basics done, I also set myself a couple of stretch goals:
- Write a Gradle plugin for my assembler
- Write an IntelliJ plugin for my assembler
I chose both of these because they’d definitely be nice things to have, and also because I hadn’t done either of them before so it would be a good learning experience 🙂
But… Why?
This is the obvious question, and sure, a Java assembler isn’t something that most people would consider useful at all (otherwise I guess there’d be more competition :D).
For me, though, playing around with the JVM, bytecode, JNI and other “low level” bits of the Java ecosystem is, well, tons of fun. It’s my happy place.
Given this was my vacation time, that seemed good enough. As for why I’m sharing it, well, I can’t be the only person who’s interested in this stuff, and as it turns out there might actually be some (admittedly narrow) use-cases for it too. So here we are.
How It Went
First Steps – Friday Night / Saturday
I made a small start on the project after work on the Friday, and by Saturday (30th April) I had the basics in place, enough to make the initial commit to Github. I did a bit more work that day, adding support for the most basic instructions (non-dynamic INVOKEs, IF_ACMP, NEW, DUP etc).
Because I was TDDing the development, I also added support for implementing interfaces pretty early on, so that in my end-to-end tests I could assemble code to classes which I could instantiate and cast to a Java interface for ease of use in the tests. For example you can see here that I was using reflection to invoke test methods, but once I’d gotten implements working I was able to cast to a Java interface for nicer test code.
Sunday
On the Sunday, I made my first major change of direction, when I decided I’d not done Kotlin in a while, and I wanted to flex those muscles a bit too. So I rewrote what I had so far in Kotlin, with a view that it would be nice to keep working in that language for the rest of the week. I also repackaged the whole thing for Java 9 modules at that point.
As it turned out, the Kotlin rewrite really got things moving – I seriously doubt I’d have gotten as far in the allotted time if I hadn’t done that early on. If you haven’t tried Kotlin I can highly recommend it – everything is just easier in Kotlin, and the fact that it’s so much fun really helps maintain velocity. The interop with Java is really great too, much better than I’ve found with other languages (I’m looking at you, Scala).
Another highlight on the Sunday was initial support for INVOKEDYNAMIC and friends, which was something I was very keen to get working. I also did a lot of work with arrays and primitives to round out the day.
Monday
With the arrival of weekdays, I didn’t have as much time as I’d dedicated at the weekend (I did want to do some non-technical stuff with my time off, after all!).
That said, I still found time to address some syntax issues that had become a bit of an elephant in the room (specifically I had a bunch of hacks in place around types and method descriptors). I did some major surgery on the grammar to redesign the syntax in a more sane way, and that stood me in good stead for the rest of the week.
The new syntax still broadly follows JVM internal names, however it dispenses with the need to terminate Lcom/whatever/Class; with a semicolon, and also allows me to optionally support Java naming for primitives (so long can be used interchangeably with J for example). As a trade-off, descriptors always require commas between types (so, for example a method that takes two ints and returns void would look like (I,I)V rather than the (II)V used internally by the JVM) – this saved my sanity a bit and helps both avoid hacks in the lexer and prevent a bit of backtracking in the parser.
With that done, I had a syntax I was happy with, and even complex things were easy to do and sane(ish) to read. For example, an INVOKEDYNAMIC using the LambdaMetafactory and various features looks like this:
public doBasicInvokeDynamicTest()Ljava/lang/String {
invokedynamic get()Ljava/util/function/Supplier {
invokestatic java/lang/invoke/LambdaMetafactory.metafactory(
Ljava/lang/invoke/MethodHandles$Lookup,
Ljava/lang/String,
Ljava/lang/invoke/MethodType,
Ljava/lang/invoke/MethodType,
Ljava/lang/invoke/MethodHandle,
Ljava/lang/invoke/MethodType
)Ljava/lang/invoke/CallSite
[
()Ljava/lang/Object,
invokestatic com/roscopeco/jasm/model/TestBootstrap.lambdaGetImpl()Ljava/lang/String,
()Ljava/lang/String
]
}
invokeinterface java/util/function/Supplier.get()Ljava/lang/Object
checkcast java/lang/String
areturn
}Tuesday – Friday
I found (and fixed) my first bug on the Tuesday!
Other than that bit of excitement, most of my project time for the rest of the week was spent just adding in support for new instructions, usually in blocks (still following TDD with lexer and parser tests, then end to end tests to ensure the code generation actually worked) but sometimes individually.
For example, I added most of the math instructions for each primitive type in a single block (such as here for int stuff, and here for long). More complex instructions went in as their own piece of work (like LOOKUPSWITCH and TABLESWITCH).
I also made some changes to the structure of the project, and especially the tests, as I went, in order to save time and make the goal more achievable. For example, as the number of test cases grew with the number of supported instructions, it made sense to parameterise a lot of the test cases, as many of them were very similar.
Saturday
By the time Saturday May 7th rolled around, I was ready to implement the final outstanding instruction – TABLESWITCH. That actually went in in the early hours, so really it was late on Friday rather than actually on the Saturday, but there you go.
After the late night, I spent a bit of time on the Saturday tidying a few things up and writing a command-line tool to invoke the assembler.
Sunday
With most of the work on the core code done, I spent a bit of time on Sunday writing some docs, and actually made a start on one of my stretch goals – writing a Gradle plugin!
Due to not having much time, the Gradle plugin is very much hacked together and was done in one commit on that Sunday, but it does work well enough to build Jasm code with Gradle, so I’m calling it a win.
I’m slightly sad that I didn’t get around to the IntelliJ plugin, but not surprised if I’m honest (and there’ll be plenty of time to circle back to that in the future).
The Week In Review
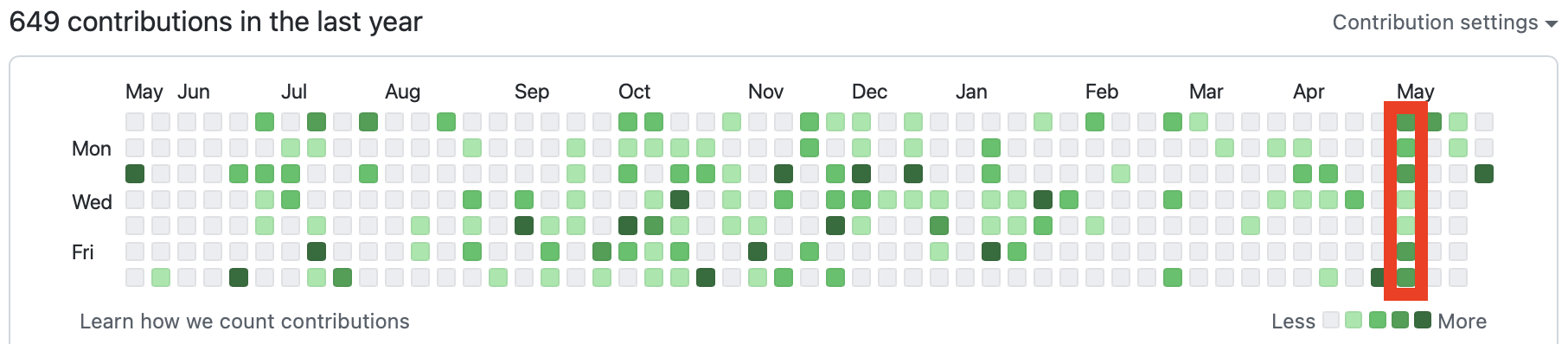
The above shows my Github contribution graph, with my vacation week highlighted in red. You can see that, while I did something every day, there was definitely a lot more activity at the weekends due to me taking time in the week to do other things. The busiest day was actually the Saturday (which falls outside the red box, to the bottom-left, due to the way weeks are shown here from Sunday – Saturday).
Was I happy with how it went? You bet I was! I hit my goal of writing a new assembler for the JVM, got to use a bunch of technologies I wanted to upskill on, and even hit one of my stretch goals. All-in-all, I’m calling the week a success 🎉
The Future
Availability
Due to time constraints, I didn’t make the projects available on Maven Central or the Gradle plugin repository immediately.
However, I had a bit of time this past weekend to come back to it and tidy things up, so Jasm is now available on Maven central. To use it in Gradle, you can just do
dependencies {
implementation("com.roscopeco.jasm:jasm:0.1")
}You can also download the first public release as a zip or a tarball, including the scripts that wrap running Jasm from the command line, from the Releases page on Github.
The Gradle plugin is currently awaiting approval for the Gradle plugin repository, but in the meantime you can grab the code and do:
./gradlew publishToMavenLocalif you want to play around with it (but note, you’ll need to configure your gradle build to take account of your local Maven repo – which you can do by adding the following to settings.gradle.kts (not build.gradle.kts):
pluginManagement {
repositories {
mavenLocal()
gradlePluginPortal()
}
}There is an example project here that shows how you might set this up, but the documentation is slightly outdated (and will be updated if/when the Gradle plugin is approved for release).
Will I be maintaining this?
In short, yes. I’ve had a lot of fun with this project, but I’ve also found it to be useful for a variety of things already, so I’ll definitely be expanding it, developing it and maintaining it going forward.
As always, Jasm is open source (MIT license) and ideas, suggestions, help and (especially) pull requests are always welcome!